
ในวิชาวิทยาการคำนวณ ม.5 มีตัวชี้วัดวิทยาการคำนวณ หรือ ว.4.2 อยู่เพียงข้อเดียวครับ
ว4.2 ม.5/1 รวบรวม วิเคราะห์ข้อมูล และใช้ความรู้ด้านวิทยาการคอมพิวเตอร์ สื่อดิจิทัล เทคโนโลยีสารสนเทศในการแก้ปัญหาหรือเพิ่มมูลค่าให้กับบริการหรือผลิตภัณฑ์ที่ใช้ในชีวิตจริงอย่างสร้างสรรค์
ซึ่งพูดง่ายๆ ก็คือนักเรียนจะต้องรวบรวมข้อมูลมาวิเคราะห์และนำเสนอเพื่อให้ผู้อ่านเข้าใจได้ทันทีว่าข้อมูลเหล่านั้นหมายถึงอะไร พร้อมกับนำไปแก้ปัญหาหรือเพิ่มมูลค่ากับสิ่งที่ต้องการได้ครับ
สำหรับผมแล้วการวิเคราะห์ข้อมูลหรือประมวลผลนั้นไม่ค่อยยากเท่าไหร่ เพราะเรามีโปรแกรมช่วยเยอะ ทั้ง Excel SPSS หรือ Tableau ครับ แต่กระบวนการในการได้มาซึ่งข้อมูลที่ต้องการนั้นเป็นสิ่งสำคัญ เช่น ถ้าเราต้องการถึงข้อมูลจำนวนมากจากเว็บไซต์หนึ่ง เราจะมีวิธีการอย่างไรจึงจะสะดวกที่สุด และข้อมูลนั้นอยู่ในรูปที่สามารถนำมาประมวลผลได้ง่าย
ในบทความนี้ผมจะอธิบายและยกตัวอย่างการทำ Web Scraping ซึ่งเป็นกระบวนการรวบรวมข้อมูลจากเว็บไซต์ใดๆ ที่ได้มาจากการอบรมครูแกนนำวิทยาการคำนวณ ม.ปลาย ครับ
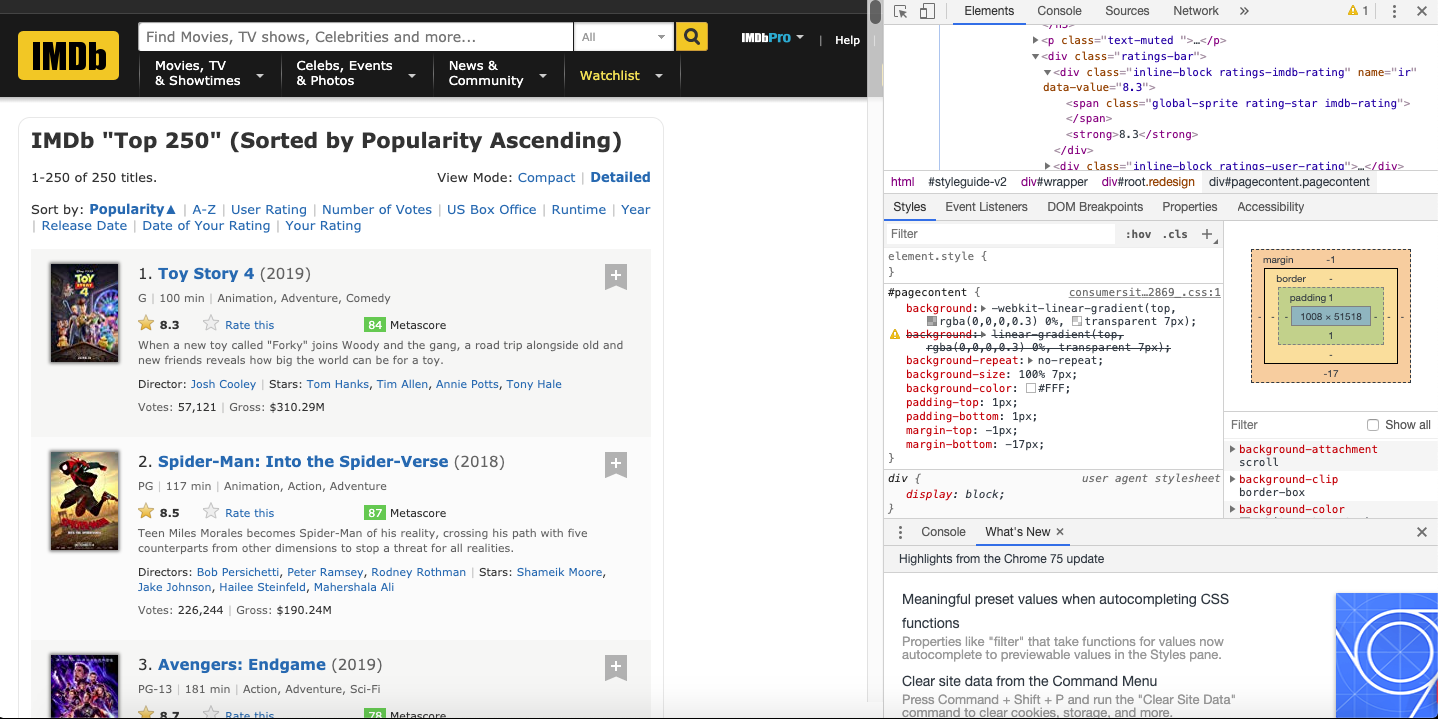
คุณครูลองทำตามเอกสารที่แนบมาดังนี้ได้เลยนะครับ ตัวอย่างที่เขียนมาจะเป็นการดึงข้อมูลภาพยนตร์จากเว็บไซต์ imdb.com 250 อันดับแรกที่ได้รับความนิยมสูงสุด โดยเลือกที่จะดึงชื่อ ปีที่ฉาย และเรทติ้งครับ (โค้ดอยู่ด้านล่างนะ)
หมายเหตุ ครูควรทดลองทำการดึงข้อมูลหลายๆ รูปแบบเพื่อให้เกิดความเข้าใจ และควรแนะนำหรือสอน HTML Element ด้วยนะครับ
http://www.nattapon.com/wp-content/uploads/2019/07/เอกสารแนะนำการรวบรวมข้อมูลด้วย-Web-Scrapping.pdf
| #นำเข้าไลบรารี | |
| from bs4 import BeautifulSoup | |
| import pandas as pd | |
| import requests | |
| import re | |
| #กำหนด URL ที่ต้องการดึงข้อมูล | |
| url = 'https://www.imdb.com/search/title/?groups=top_250&count=250' | |
| response = requests.get(url) | |
| #ใช้ BeautifulSoup ดึง HTML content | |
| page_html = BeautifulSoup(response.text, 'html.parser') | |
| #ดึงข้อมูลที่ต้องการ | |
| movie_containers = page_html.find_all('div', class_='lister-item mode-advanced') | |
| names = [] | |
| years = [] | |
| imdb_ratings = [] | |
| # For every movie of these 50 | |
| for container in movie_containers: | |
| # Scrape the name | |
| name = container.h3.a.get_text(strip=True) | |
| names.append(name) | |
| # Scrape the year | |
| year = container.find('span', 'lister-item-year text-muted unbold').get_text(strip=True) | |
| year = re.search('\d{4}', year).group(0) | |
| years.append(year) | |
| # Scrape the IMDB rating | |
| imdb_rating = container.strong.get_text(strip=True) | |
| imdb_ratings.append(float(imdb_rating)) | |
| imdb_df = pd.DataFrame({ | |
| 'movie': names, | |
| 'year': years, | |
| 'imdb_rating':imdb_ratings, | |
| }) | |
| imdb_df.to_csv('movie_data.csv') |
 by
by 



อาจารย์ครับ ผมอยากได้ไฟล์เอกสารที่อาจารย์สอนการดึงข้อมูลจากเวบไซต์ไปอ่านเอง ไม่ทราบว่าจะสั่งปริ้นท์ได้ยังไงครับ